
1. Introduction
DeepSeek has become very popular recently. You can use it for free online. However, their server is still unstable, and it may stop working just as you’re happily in the middle of something. So, I think you can try downloading the model to use it, but of course, there will be some limitations to that, which I will show you later.
2. Which Models Should You Use Locally?
You can’t choose which version to use in the DeepSeek online version, but you can download other versions to use on your computer locally.
Ok, but there are many types of models of DeepSeek below:
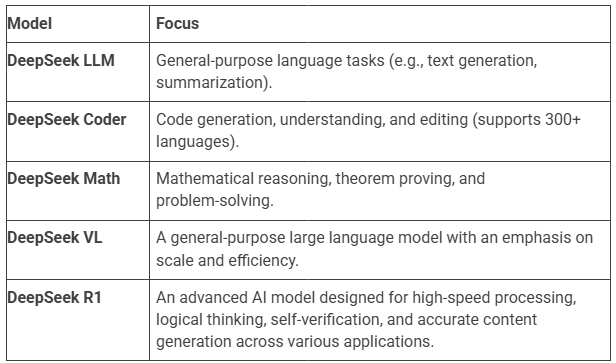
DeepSeek LLM
DeepSeek Coder
DeepSeek Math
DeepSeek VL
DeepSeek V2
DeepSeek Coder V2
DeepSeek V3
DeepSeek R1
Even in each model, there are still many types, something like
1.5b, 7b, 8b, 14b, 32b, 70b, 671b, etc.
So, which one should you use? And what’s the difference?
Ok, let me show you!
1) Model Specialization
Different DeepSeek models are optimized for distinct tasks:
2) Parameter Sizes (1.5B, 7B, 33B, etc.)
Larger models generally have stronger performance but require more resources
3) Model Versions (V1, V2, V3)
Iterations improve performance, efficiency, or specialization
- V1: Baseline architecture.
- V2/V3: Enhanced training data, optimized architectures (e.g., MoE for efficiency), or extended context windows.
- Example: DeepSeek Coder V2 might support longer code contexts than V1, while DeepSeek V3 could use sparse activation for lower inference costs.
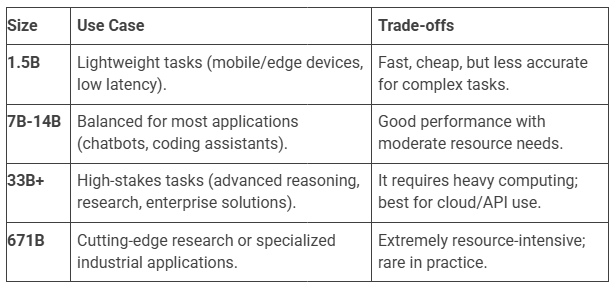
So, if you don’t need to handle some special tasks (e.g. coding or mathematical operations), I suggest you focus on the DeepSeek VL or R1 model. About the parameter sizes, they need to be based on your computer configuration. You can find the below table for your reference:

You can use the below formula to calculate the RAM:
- Full-Precision (FP32):
Memory (GB)=Parameters×4 bytes
(e.g., 7B parameters = 7×4=28 GB) - Half-Precision (FP16/BF16):
Memory (GB)=Parameters×2 bytes
(e.g., 7B parameters = 7×2=14 GB) - 8-bit Quantization:
Memory (GB)=Parameters×1 byte
(e.g., 7B parameters = 7×1=7 GB)
For my example, I am using a Mac Mini M4 with 32G RAM and I can use up to the 32B size. But it also needs to be based on what AI Model Management System you are using, for example, if I use LM Studio by default settings with DeepSeek R1 32B Model, it would hang and auto-restart my device, but if I use Chatbox or Open-WebUI then that will be fine, but of course just a little slowly.
A Comprehensive Guide to AI Model Naming Conventions
1. Introduction
3. How to download the models to use?
1) You can download the AI models from Hugging Face with Python.
In this way, you need to write the codes and handle the UI yourself, but the advantage is you can use all of the models in Hugging Face.
For example, download the DeepSeek 1.5B model below with transformers from Hugging Face:
# import transformers library
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# the model name in Hugging face
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
# Load with explicit MPS configuration
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="mps", # Directly specify MPS
torch_dtype=torch.float16, # Force FP16 for MPS compatibility
low_cpu_mem_usage=True # Essential for 8GB RAM
).eval() # Set to eval mode immediatelyYou can also use the gradio to generate a simple UI
import gradio as gr
# Define the function to generate text
def generate_text(prompt, max_length=100, temperature=0.7):
inputs = tokenizer(prompt, return_tensors="pt").to("mps")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Create a Gradio interface
demo = gr.Interface(
fn=generate_text,
inputs=[
gr.Textbox(lines=3, placeholder="Enter your prompt..."),
gr.Slider(50, 500, value=100, label="Max Length"),
gr.Slider(0.1, 1.0, value=0.7, label="Temperature")
],
outputs="text",
title="DeepSeek-R1-Distill-Qwen-1.5B Demo",
description="A distilled 1.5B parameter model for efficient local AI."
)
# Launch the interface
demo.launch(share=True)
# Access via http://localhost:7860Run the above codes, you will download the DeepSeek-R1-Distill-Qwen-1.5B model and create a localhost server as below
HTTP://localhost:7860
You will find the result below
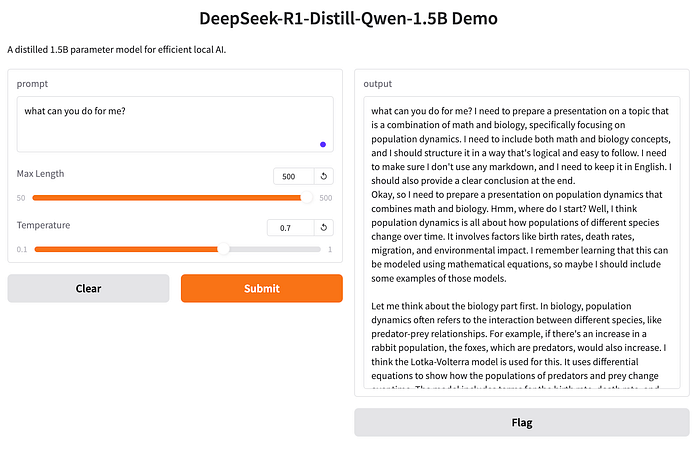
But this is not easy to use and not friendly enough.
2) Use Ollama to download the models
This is the easy way to host a local LLMs.
Download and install the Ollama from https://ollama.com/ . After installed the Ollama, you can run the Ollama command in console ( Terminal on MacOS, Command line on Windows)
For example, we want to download the DeepSeek R1 Distill 1.5B model, go to https://ollama.com/search search the DeepSeek model, and you will find many models
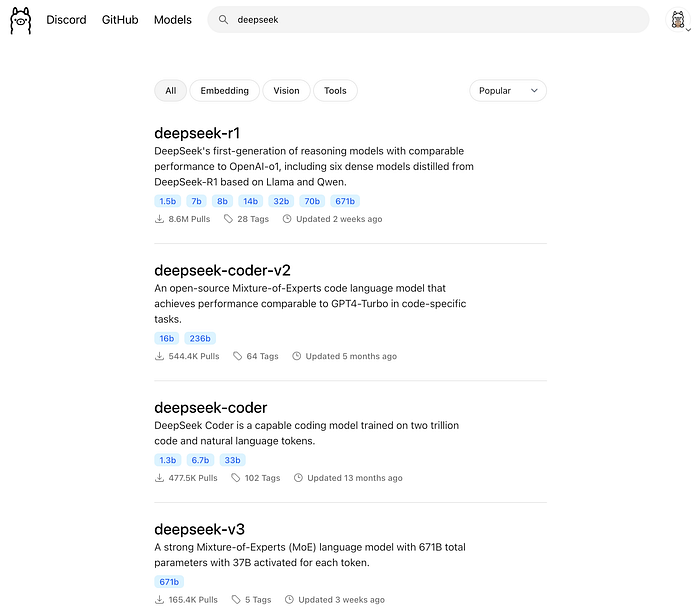
Just click the first one (deepseek-r1), choose the tags to 1.5b and click the right side’s copy button
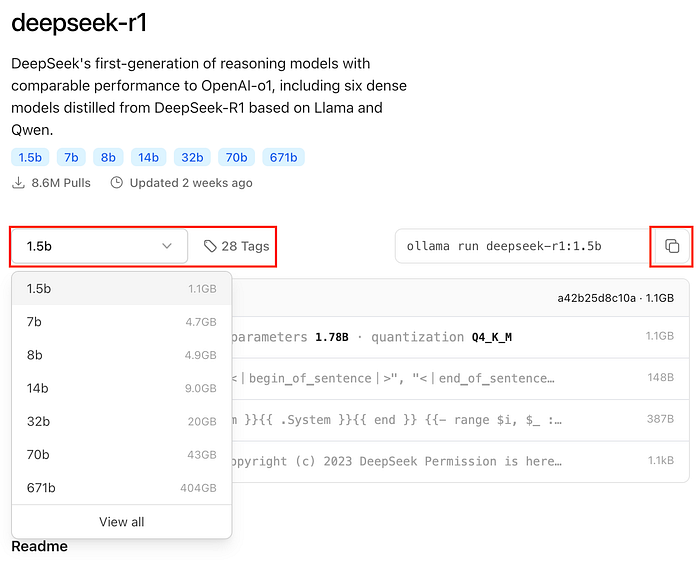
Run the command
ollama run deepseek-r1:1.5b
It will start downloading the model at first time, after the model downloaded, will shoe below and you can input the prompt to use
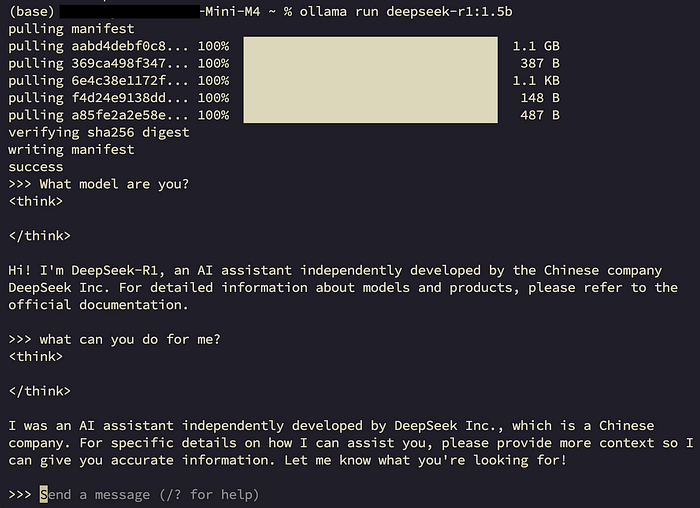
You will find that also can not be used as well, so we need a LLM management tool for handle the UI to let’s easy to use the model.
The Powerful Novel Generator by AI
1. Introduction
Go to https://www.chatboxai.app/ to download the latest version.
Open the Chatbox app, click Settings in the left side, and set the model provider to OLLAMA API, it will auto-detect all of the downloaded models in Ollama
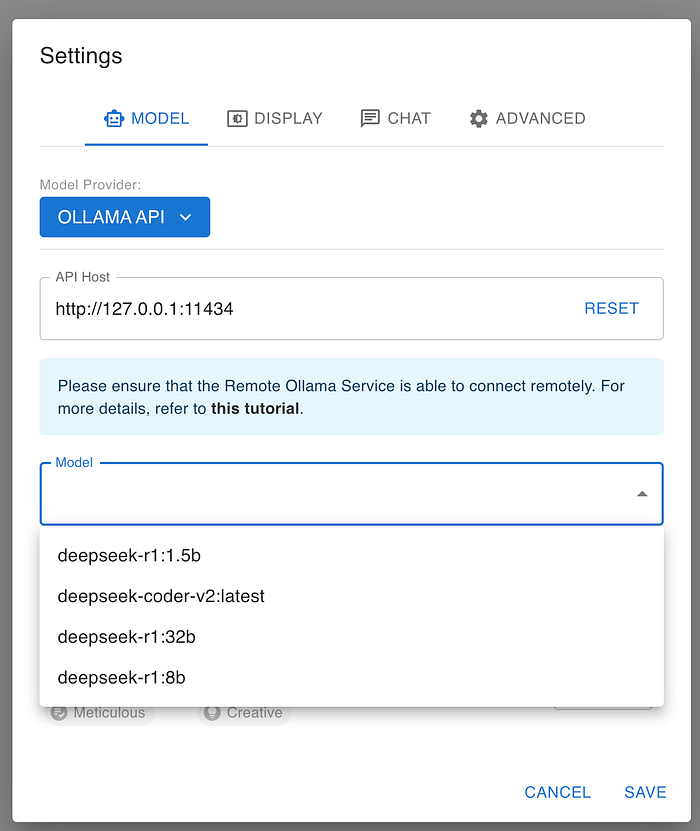
When you create a new chat, you can switch to a different model at any times
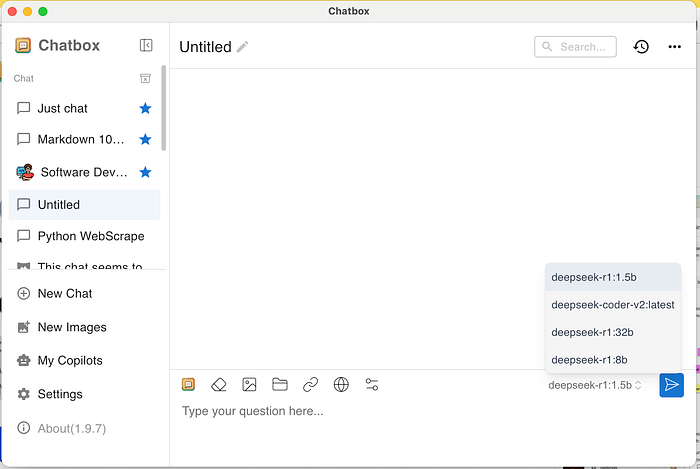
Seems great now
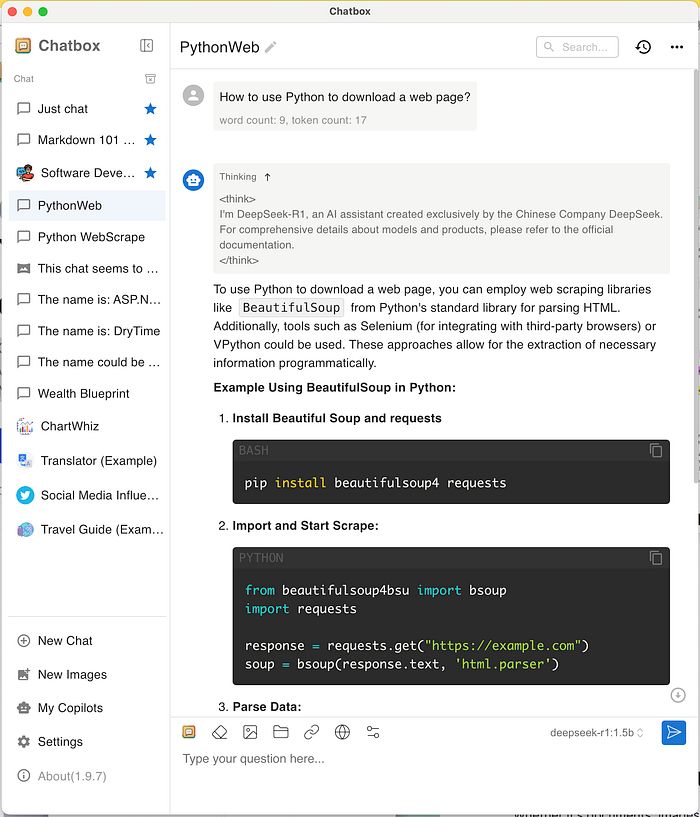
Ok, there are still other tools for that, such as:
LM Studio: https://lmstudio.ai/
This is also a very nice application for handling AI models, but don’t know why it will cash my OS (auto-reboot) when I try to run the DeepSeek R1 32B model, and that’s fine in Chatbox app.
Another one is Open-Web UI : https://openwebui.com/
It is an extensible, self-hosted (web) AI interface that adapts to your workflow, all while operating entirely offline.
Please let me know if you find another better application 🙂
![]()
About the Author
Related posts:
 Create Angular Project and Communicate with .Net Core
Create Angular Project and Communicate with .Net Core
 How to use code first and data migration with ServiceStack.OrmLite
How to use code first and data migration with ServiceStack.OrmLite
 How to Implement JWT in Core API and Angular — Part 2
How to Implement JWT in Core API and Angular — Part 2
 Use the Repository pattern in .Net core
Use the Repository pattern in .Net core
 The Art of Service Registration: Writing Clean and Scalable IServiceCollection Extensions
The Art of Service Registration: Writing Clean and Scalable IServiceCollection Extensions



